Writing WAX Plug-Ins
- Author:
- Serge Monkewitz
| Contents | |
Getting started
The following documentation assumes that WAX has been installed and that the reader is familiar with compiling and running WAX. Finally, proficiency in C is a must.Writing a plug-in: first steps
Before beginning the task of writing a plug-in, it is important to understand what the plug-in interface allows a programmer to accomplish within the WAX software framework. The plug-in interface cannot be used to change or replace the behaviour of the swiss cheese algorithm - that is : it cannot be used to generate groups, to add apparitions to or remove apparitions from groups, nor to modify any of the standard group attributes calculated by the swiss cheese algorithm.A plug-in can however compute ancillary attributes for both groups and apparitions. For a group, these might include the average position and magnitudes of apparitions belonging to the group. For an apparition, these might include an identifier for the "best" group containing the apparition.
Plug-in goals
With this in mind, the plug-in writer must first decide which attributes he or she wishes to compute, as well as the input apparition table to generate groups for.To illustrate each of the steps in writing a plug-in, an example will be developed alongside the explanatory text. Information specific to the example will be presented inside boxes with a light-blue borders.
| Example Goals |
For each group :
|
For each apparition, given a list of groups containing the apparition, find the one with average position closest to the apparition, and :
|
The example plug-in will be used to process the 2MASS 6X2 Survey Point Source Table, sixx2@rmt_pebble:pt_src_6x2_01.
|
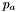
Creating a plug-in directory
Next, a working directory for the plug-in files must be created - this should be a subdirectory of the WAX installation directory.
% cd /my_wax_install
% mkdir my_wax_plugin
Then, the template files must be copied over :
% cd my_wax_plugin
% cp ../template/* .
The example plug-in is located in the wax_example subdirectory of the WAX installation directory : |
Editing the template files
For an explanation of what each of the template files are, please see this documentation section.
The first file to edit is retrieve.tbl, the retrieval column file. This file should be edited to list the names of all the columns which must be retrieved from the input apparition table in order to compute the desired group and apparition attributes.
The example WAX plug-in requires only the position of each apparition for its computations. Since the WAX software automatically retrieves those, the retrieve.tbl file should be left as is, empty. |
The next file to edit is output.tbl, the output column file. This file should be edited to list the names and Informix types of all the columns corresponding to group attributes. The file essentially dictates the database schema for the group information table.
Here is the output.tbl file for the example WAX plug-in:
|
The grpapp.tbl file is the grouped apparition column file, and must be edited to list the names and Informix types of all the columns corresponding to apparition attributes. This dictates the database schema for the grouped apparition table.
Here is the grpapp.tbl file for the example WAX plug-in:
|
The final file to edit is gen.sh. This file is described in detail here, and is essentially a wrapper script which supplies arguments to the source generation helper application. It must be edited to specify the apparition table to use, the name of the plug-in, etc...
Here is the gen.sh shell script, with comments stripped, for the example WAX plug-in :
|
Generating plug-in source code
After the above steps have been completed, thegen.sh shell script must be run. This will generate several source/script files, documented in detail here. Editing the source code
The source generation helper application will generate an empty implementation of the plug-in interface (declared insummary.h) in a C file named summary[_name].c. This is the file which must be edited to process groups and apparitions. Available libraries
The code in the generatedsummary[_name].c file will always begin by including several header files, making a wide variety of library functions available to the plug-in code :
|
These header files, described below
common.h- Contains declarations for various constants, e.g. minimum and maximum search radii, various multiples of
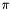 , constants for converting between radians and degrees, etc... Also provides various utility functions, including functions for converting strings to integers and floating point numbers, functions for message logging, and timing functions.
, constants for converting between radians and degrees, etc... Also provides various utility functions, including functions for converting strings to integers and floating point numbers, functions for message logging, and timing functions. vector.h- This header file declares the
radec_t(representing a position as a right ascension and declination) andvec3_t(a vector in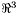 ) structures, as well as functions operating on them. These include functions for computing the vector cross and inner products, functions for vector normalization and magnitude, etc... Note that
) structures, as well as functions operating on them. These include functions for computing the vector cross and inner products, functions for vector normalization and magnitude, etc... Note that RaDecis an alias forstruct radec_t, andVec3an alias forstruct vec3_t appgroup.h- This header file declares the
app_t(representing an apparition) andgroup_t(representing a group) structures.Appis an alias forstruct app_t, andGroupan alias forstruct group_t. Together, these structures contain all standard attributes (both retrieved and computed) for apparitions and groups. The data corresponding to the specified retrieval columns is available viaApp::info, which is a pointer to anapp_info_t(AppInfo) structure that is declared in the generatedinfo[_name].hheader file. The data corresponding to the specified group attributes (output columns) is available fromGroup::info, a pointer to agroup_info_t(GroupInfo) structure, also declared in theinfo[_name].hheader file. Finally, the data corresponding to the desired apparition attributes (grouped apparition columns) is stored in structures of typegrouped_app_info_t(GroupedAppInfo). info[_name].h- This header file, generated by the source generation helper application, declares C structures corresponding to the desired retrieval columns, group attributes, and apparition attributes. Please examine the actual file for details, as they depend on the ASCII tables edited above.
putil.h- This header file declares functions for loading BSP tree files, computing scan coverage, and for computing the spatial index of a position.
summary.h- This header file declares the C functions which must be implemented by the plug-in writer.
Implementing the plug-in interface
The following functions must be implemented :
initProcess()- This function allocates resources needed by
processGroup(),processSingle(), andprocessApparition(). freeProcess()- This function releases any resources allocated by
initProcess(). processGroup()- This function computes group attributes for groups containing at least 2 apparitions.
processSingle()- This function computes group attributes for groups containing exactly 1 apparition.
processApparition()- This function computes apparition attributes, and is called only after attributes have been computed for all groups.
Example implementation
Here is the source code for the example plug-in (obtained fromsummary_example.c):
/*
----------------------------------------------------------------
Copyright (C) California Institute of Technology. All
rights reserved. US Government Sponsorship is acknowledged.
----------------------------------------------------------------
*/
/**
\file summary_wsdb.c
\author This file was generated by the
WAX source generation utility
\date Wed Sep 8 22:43:44 2004
*/
static double sgSinRad;
/* Allocates resources for group/apparition processing */
void initProcess(const double rad,
const double decmin,
const double decmax)
{
/* Precompute the sine of the grouping radius. */
sgSinRad = sin( gRadPerDeg * (rad / 3600.0) );
/* Load the BSP files for the band being processed. */
loadBsp(decmin, decmax, TRUE);
}
/* Releases resources allocated for group/apparition processing */
void freeProcess()
{
/* Nothing to do here */
}
/* Processes a group containing at least two apparitions */
int processGroup(Group * const grp,
const size_t napp,
const App * const * const list)
{
Vec3 avgpos;
RaDec avgloc;
GroupInfo * ginfo;
const App * const * a;
const App * const * alim;
const App * app;
/* Get a pointer to the GroupInfo structure
to store computed attributes in */
ginfo = grp->info;
/* Set the initial average position to the zero vector */
avgpos.x = 0;
avgpos.y = 0;
avgpos.z = 0;
/* Loop over all apparitions in the group, adding the
vector position of each one to avgpos */
a = list;
alim = list + napp;
while (a < alim)
{
app = *a;
++a;
vadd2(&avgpos, &(app->pos));
}
/* normalize the sum of all the apparition positions,
obtaining an average position for the group */
vnormalize(&avgpos);
/* convert the average position vector to a right ascension
and declination */
vtord(&avgloc, &avgpos);
/* store the average position in the GroupInfo structure */
ginfo->ra = avgloc.ra;
ginfo->dec = avgloc.dec;
ginfo->x = avgpos.x;
ginfo->y = avgpos.y;
ginfo->z = avgpos.z;
/* Compute the HTM index for the groups average position */
getSpatialIndex( &avgpos, &(ginfo->spt_ind) );
/* Compute the minimum and maximum scan coverage for a circular
region centered on the groups average position with a radius
equal to the group radius. */
overlapRange(
&avgloc,
&avgpos,
sgSinRad,
&(ginfo->smin),
&(ginfo->smax)
);
/* Compute scan coverage for the groups average position */
overlapRange(
&avgloc,
&avgpos,
0.0,
&(ginfo->spos),
&(ginfo->spos)
);
/* return the GROUP_OK constant to indicate that this group
should be inserted into the output tables */
return GROUP_OK;
}
/* Processes a group containing a single apparition */
int processSingle(Group * const grp,
const App * const app)
{
GroupInfo * ginfo;
/* Get a pointer to the GroupInfo structure
to store computed attributes in */
ginfo = grp->info;
/* The average group position is identical
to the apparition position */
ginfo->ra = (app->loc).ra;
ginfo->dec = (app->loc).dec;
ginfo->x = (app->pos).x;
ginfo->y = (app->pos).y;
ginfo->z = (app->pos).z;
/* Compute the HTM index for the groups average position */
getSpatialIndex( &(app->pos), &(ginfo->spt_ind) );
/* Compute the minimum and maximum scan coverage for a circular
region centered on the groups average position with a radius
equal to the group radius. */
overlapRange(
&(app->loc),
&(app->pos),
sgSinRad,
&(ginfo->smin),
&(ginfo->smax)
);
/* Compute scan coverage for the groups average position */
overlapRange(
&(app->loc),
&(app->pos),
0.0,
&(ginfo->spos),
&(ginfo->spos)
);
/* return the GROUP_OK constant to indicate that this group
should be inserted into the output tables */
return GROUP_OK;
}
/* Processes an apparition */
void processApparition(const App * const app,
GroupedAppInfo * const gainfo,
const size_t ngrp,
const Group * const * const list)
{
double dp, maxdp;
const Group * const * g;
const Group * const * glim;
const Group * grp;
const Group * best;
const GroupInfo * ginfo;
if (ngrp == 1)
{
/* there is only one choice for the "best" group */
best = *list;
}
else
{
/* Set the maximum dot product to -2 (smaller than
any dot product of two unit vectors) */
maxdp = -2.0;
/* Loop over all groups containing the apparition, finding the
one with average position closest to the apparition */
g = list;
glim = list + ngrp;
while (g < glim)
{
grp = *g;
++g;
ginfo = grp->info;
/* compute the dot-product of the apparition position
and the group average position */
dp = (app->pos).x * (ginfo->x) +
(app->pos).y * (ginfo->y) +
(app->pos).z * (ginfo->z);
/* if this dot product is greater than the previous
maximum dot product, then grp is closer to app than
best, so set best to equal grp */
if (dp > maxdp)
best = grp;
}
}
/* Now the best group is known. Copy its attributes to gainfo */
gainfo->ngrp = ngrp;
gainfo->best_gcntr = best->gcntr;
gainfo->best_napp = best->napp;
gainfo->best_gtype = best->gtype;
gainfo->best_sdet = best->sdet;
ginfo = best->info;
gainfo->best_smin = ginfo->smin;
gainfo->best_smax = ginfo->smax;
gainfo->best_spos = ginfo->spos;
/* all done */
}
/* ---------------------------------------------------------------- */
/* ================================================================ */
|
Compiling and running the example
Simply run the generated make script to compile the example WAX executable :
% make_example.sh
wax_example. Generating BSP files
The example plug-in uses theoverlapRange() function to compute scan coverage, which internally uses BSP trees. To generate these BSP trees, the bspgen helper application must be run on an ASCII scan corner file :
% cd ../bsp_example
% ../bin/bspgen scanex.4cvecs.nds . -v -p
% cd ../wax_example
/my_wax_install/bsp_example directory. Dropping and creating output tables
Next, the output tables which the WAX executable inserts rows into must be created. For the purposes of the example, they will be namedex_info (for group attributes), ex_link (links between groups and apparitions), and ex_gapp (apparition attributes). To create these tables in the ipac@rmt_gravel database, run wax_example as follows :
% wax_example -create "ipac@rmt_gravel" ex_info ex_link -grpapp ex_gapp -v
To drop them, run
% wax_example -drop "ipac@rmt_gravel" ex_info ex_link -grpapp ex_gapp -v
Running the example WAX executable
To generate groups using a 2 arcsecond group radius for all the primary bands contained inbands.txt (the band file), run wax_example as follows:
% wax_example -pri 0-482 bands.txt 2.0 . "sixx2@rmt_pebble:pt_src_6x2_01" \
"ipac@rmt_gravel" ex_info ex_link -v -p -grpapp ex_gapp \
-bsp ../bsp_example
To do the same for the secondary bands (which must always be processed after the primary bands have completed):
% wax_example -sec 0-482 bands.txt 2.0 . "sixx2@rmt_pebble:pt_src_6x2_01" \
"ipac@rmt_gravel" ex_info ex_link -v -p -grpapp ex_gapp \
-bsp ../bsp_example
See this page for in-depth documentation on the command line arguments accepted by WAX executables.
Generated on Thu Oct 21 13:19:39 2004 for WAX Version 2.1 by